Igor Sunday Pandzic1, Tolga K. Capin2,
Nadia Magnenat Thalmann1, Daniel Thalmann2
1 MIRALab - CUI
University of Geneva
24 rue du Général-Dufour
CH1211 Geneva 4, Switzerland
{Igor.Pandzic,Nadia.Thalmann}@cui.unige.ch
http://miralabwww.unige.ch/
2 Computer Graphics Laboratory
Swiss Federal Institute of Technology (EPFL)
CH1015 Lausanne, Switzerland
{capin, thalmann}@lig.di.epfl.ch
http://ligwww.epfl.ch/
Following the success of MPEG-1 and MPEG-2 standards, the MPEG group is currently working on MPEG-4, which is scheduled to become an International Standard in November 1998. The new standard moves forward from the model of video as a sequence of uniformely sized and shaped images with attached audio information. The video scene consists of audio and video objects that are spacially and temporally independent, and as such can be stored, transferred and manipulated separately, to be composited by the decoder, potentially leaving large freedom of manipulation to the consumer of information and preserving a high level data structure. Flexibility and scalability are other key issues addressed by the new standard. Possibly the most radical change with respect to the current standards will be the inclusion of synthetic audio and video data in the standard. The Synthetic/Natural Hybrid Coding (SNHC) group is the MPEG body that deals with these topics. SNHC consists of subgroups covering several differnet aspects of the subject: Face and Body Animation, Generic Object Coding, Media Integration of Text and Graphics and SNHC Audio. We present in particular detail the work of Face and Body Animation group, whose goal is to standardize a compact yet versatile representation of human bodies and faces, as well as naturally-looking animations of such for applications ranging from low bitrate videophones to collaborative work in 3D virtual environments.
MPEG-1 and MPEG-2 are widely used standards for coding of audio-visual data. Now the Moving Pictures Experts Group is working on the new standard - MPEG-4 - which is scheduled to become an International Standard in November 1998.
In a world where audio-visual data is increasingly stored, transferred and manipulated digitally, MPEG-4 sets itsobjectives beyond "plain" compression [1]. Instead of regarding video as a sequence of frames with fixed shape and size and with attached audio information, the video scene is regarded as a set of dynamic objects. Thus the background of the scene might be one object, a moving car another, the sound of the engine the third etc. The objects are spatially and temporally independent and therefore can be stored, transferred and manipulated independently. The composition of the final scene is done at the decoder, potentially allowing great manipulation freedom to the consumer of the data.
Flexibility and scalability are major issues in MPEG-4 and will be adressed by defining different profiles and levelsand introducing a possibility of a negotiation phase between encoder and decoder.
Video and audio acquired by recording from the real world are considered as natural objects. In addition to the natural objects, MPEG-4 aims to enable integration of synthetic objects within the scene. Synthetic, computer generated graphics and sounds are being produced and used in ever increasing quantities and it is the role of the Synthetic/Natural Hybrid Coding (SNHC) group of MPEG to integrate the coding of these objects with the natural data. In view of complexity of the task, SNHC has adopted a bottom-up approach, concentrating in the beginning on particular application fields and defining future extensions that will take place as the work proceeds. Current work of SNHC concentrates on Face and Body Animation, Generic Object Coding , Media Integration of Text and Graphics and Synthetic Audio. We will look in particular at the Face and Body Animation group. This group deals with coding of human faces and bodies, i.e. efficient representation of their shape and movement. This is important for a number of applications ranging from communication, entertainment to ergonomics and medicine. Therefore there exists quite a strong interest for standardization.
The paper is organized in a zoom-in fashion. The next section gives a brief and high-level overview of MPEG-4 subgroups. Following section focuses on the SNHC part of MPEG-4, presenting briefy various subgroups of SNHC: Face and Body Animation, Generic Object Coding, Media Integration of Text and Graphics. Finally we focus on the Face and Body Animation subgroup of SNHC and cover its work in greater detail. The last section is the conclusion.
Currently there are four groups that work on producing MPEG-4 standards: Systems, Audio, Video and SNHC. The standard will finally consist of Systems, Audio and Video parts, and the specifications produced by SNHC will be integrated in either Audio or Video.
The Systems layer supports demultiplexing of multiple bitstreams, buffer management, time identification, scene composition and terminal configuration.
MPEG-4 video provides technologies for efficient storage, transmission and manipulation of video data in multimedia environments. The key areas adressed are efficient representation, error resilience over broad range of media, coding of arbitrarily shaped video objects, alpha map coding.
MPEG-4 Audio standardizes the coding of natural audio at bitrates ranging from 2 kbit/sec to 64 kbit/sec, adressing different bitrate ranges with appropriate coding technologies.
Syntehetic/Natural Hybrid Coding (SNHC) deals with coding of synthetic audio and visual data. SNHC is described in detail in following sections.
The main task of the SNHC subgroup of MPEG is to standardize on coding of synthetic objects (2D and 3D graphics, synthetic audio) and integration of such objects with natural audio and video objects [2].
In view of complexity of the task, SNHC has adopted a bottom-up approach [3], concentrating in the beginning on particular application fields and defining future extensions that take place as the work proceeds. In its ultimate goal, SNHC aims to provide a framework for applications integrating dynamic 3D and 2D objects, 3D synthetic sound, virtual human representations, natural sound and video, data coming from local storage or streamed through the network, each object being independant and open to manipulation.
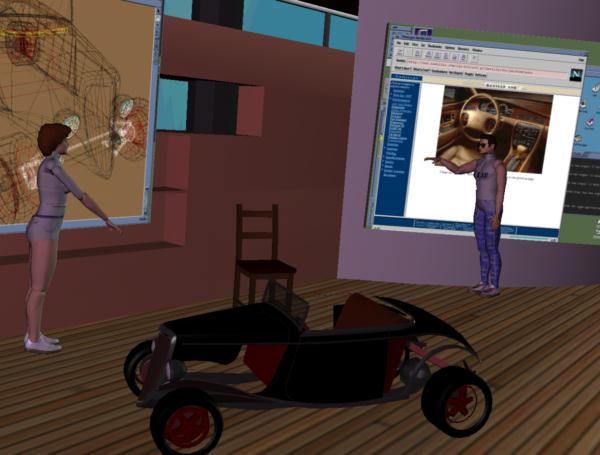
Typical application framework at this level might be the Networked Collaborative Virtual Environments allowing multi user applications such as virtual teleconferencing, collaborative 3D design, games, teleshopping, medical applications, distance learning/training etc. For illustration, figure 1 shows a snapshot from the Virtual Life Network (VLNET) [4,5], a Networked Collaborative Virtual Environment system developed by MIRALab and LIG.
In the current stage, the most important efforts in SNHC are directed towards Face and Body Animation, Generic Object Coding and Media Integration of Text and Graphics. Next few subsections provide more detail on each of these topics.
Figure 1: Snapshot from Virtual Life Network
The goal of the Face and Body Animation (FBA) group is to standardize the coding of human bodies and faces. The standard will include the definition of body/face shape and texture and provide means to compactly define animation of both face and body. The work of this group is presented in more detail in the next section.
The capability to overlay text, images and graphics upon backgrounds consisting of video sequences corresponding to existing standards, i.e., MPEG-1 and MPEG-2, as well as the emerging standard, MPEG-4, is a much desired one. In addition, it is also desired that these overlay functionalities be available in the absence of natural video and audio backgrounds. MITG will provide these functionalities and a set of functionalities to perform some basic movement operations on the overlaid graphics, as well as efficient coding of these functionalities.
Generic Object Coding deals with coding of textures and polygon meshes.
Texture coding will efficiently code images that are used as textures and mapped on polygon meshes. Because of the particularities of texture mapping technique as a way of rendering, it is possible to code the textures more efficiently without significant loss of quality in final images and/or to code a texture representation that is directly suited to the texture mapping technique.
Polygon mesh coding deals with the coding of static 2D/3D polygon meshes, as well as with techniques to efficiently code dynamic meshes, i.e. deformable objects.
SNHC Audio deals with Text To Speech (TTS) conversion, basic MIDI support and basic synthetic audio description. TTS functionality wil provide a link to the Face Object allowing synchronized generation of appropriate lip movement.
The Face and Body Animation (FBA) group deals with coding of human faces and bodies, i.e. efficient representation of their shape and movement. This is important for a number of applications ranging from communication, entertainment to ergonomics and medicine. Therefore there exists quite a strong interest for standardization. The SNHC group has issued a draft document defining in detail the parameters for both definition and animation of human faces and bodies [6]. This draft is based on proposals from several leading institutions in the field of virtual humans research. It is being updated within the current SNHC Verification Model [7].
Definition parameters allow detailed definition of body/face shape, size and texture. Animation parameters allow to define facial expressions and body postures. The parameters are designed to cover all naturally possible expressions and postures, as well as exaggerated expressions and motions to some extent (e.g. for cartoon characters). The animation parameters are precisely defined in order to allow accurate implementation on any facial/body model.
The Facial Definition Parameter set (FDP) and the Facial Animation Parameter set (FAP) are designed to allow the definition of a facial shape and texture, as well as animation of faces reproducing expressions, emotions and speech pronunciation.
The FAPs, if correctly interpreted, will produce reasonably similar high level results in terms of expression and speech pronunciation on different facial models, without the need to initialize or calibrate the model.
The FDPs allow the definition of a precise facial shape and texture in the setup phase. If the FDPs are used in the setup phase, it is also possible to produce more precisely the movements of particular facial features.
The FAPs are based on the study of minimal facial actions and are closely related to muscle actions. They represent a complete set of basic facial actions, and therefore allow the representation of most natural facial expressions. The lips are particularly well defined and it is possible to precisely define the inner and outer lip contour. Exaggerated values permit to define actions that are normally not possible for humans, but could be desirable for cartoon-like characters.
All the parameters involving translational movement are expressed in terms of the Facial Animation Parameter Units (FAPU). These units are defined in order to allow interpretation of the FAPs on any facial model in a consistent way, producing reasonable results in terms of expression and speech pronunciation. They correspond to fractions of distances between some key facial features (e.g. eye distance). The fractional units used are chosen to allow enough precision.
The parameter set contains three high level parameters. The viseme parameter allows to render visemes on the face without having to express them in terms of other parameters or to enhance the result of other parameters, insuring the correct rendering of visemes. The full list of visemes is not defined yet. Similarly, the expression parameter allows definition of high level facial expressions.
The FDPs are used to customize a given face model to a particular face. The FDPs are normally transmitted once per session, followed by a stream of compressed FAPs. However, if the decoder does not receive the FDPs, the use of FAPUs insures that it can still interpret the FAP stream. This insures minimal operation in broadcast or teleconferencing applications.
The Facial Definition Parameter set contains the following:
* 3D feature points (e.g. mouth corners & contour, eye corners, eyebrow ends etc.)
* 3D mesh (with texture coordinates if texture is used) (optional)
* texture image (optional)
* other (hair, glasses, age, gender) (optional)
The 3D mesh representation is used to define the shape of the face. It can include the texture coordinates if the texture is used. The set of 3D feature points are used to locate the facial features within the 3D shape. It is possible to use only the set of feature points as a rough description of face shape.
The Body Animation Parameters (BAPs), if correctly interpreted, will produce reasonably similar high level results in terms of body posture and animation on different body models, without the need to initialize or calibrate the model.
No assumption is made and no limitation is imposed on the number of articulation (joints) in the human body model and the range of motion of joints. In other words the human body model should be capable of supporting various applications, from realistic simulation of human motions to network games using simple human-like models.
Global Positioning Domain Parameters:
These are the global position and orientation values of particular observable points on the body, in the body coordinate system.
Possible choices: top of head, back of neck (C7-T1), mid-clavicle, shoulders (acromion), elbow, wrist, pelvis(L3-L4), hip, knee, ankle, bottom of mid-toe.
Joint Angle Domain Parameters:
These parameters comprise the joint angles connecting different body parts. Possible candidates: toes, ankle, knee, hip, the spine (C1-C7, T1-T12, L1-L5), shoulder, clavicle, elbow, wrist, and the fingers. The detailed joint list, with the rotation normals are given in the following section. The rotation angles are assumed to be positive in the counterclockwise rotation direction with respect to the rotation normal. The rotation angles are defined as zero in the default posture, as defined above.
Note that the normals of rotation move with the body, and they are fixed with respect to the parent body part. That is to say, the axes of rotation are not aligned with the body or world coordinate system, but move with the body parts.
Hand and Finger Parameters:
The hand is capable of performing complicated motions and there are at least fifteen joints in the hand, not counting the carpal part. We recommend the inclusion of the fifteen joint data, e.g. available from cyberglove.
Force Parameters:
Force parameters should be a part of the human animation system so that human body animations can be generated by applying forces of certain magnitude and direction, to specific places on the body model. The force parameters are given by specifying the direction and magnitude of the force, and the application point on the body. The position and orientation are in the body coordinate system. No assumption is made on the application point of the force (i.e. it can be on the surface or on the skeleton, or in the between).
High Level Parameters
High level parameters can be used to define high level expressions, or motions, without having to describe them by lower level parameters. The set of high level parameters and their input values have not been defined yet.
It is assumed that every decoder has a default body model with default parameters. Therefore, the setup stage is not necessary to create body animation. The setup stage is used to customize the body at the decoder.
A set of parameters can be used to customize the body models. These parameters are called Body Definition Parameters. For customization, a subset of the BDPs can be specified.
Body Definition Parameter set contains the following:
* Body surface geometry (with texture coordinates if texture is used)
* 3D reference points
* texture images (optional)
* attachment information of the geometry
* other (age, gender, etc.) (optional)
Though FAP/BAP representation already is very compact, it is desirable to further compress it. The FAPs are quantized and coded by a predictive coding scheme obtaining face control at a bitrate of approx. 2 kbit/sec.
This paper has provided a very brief overview of the future MPEG-4 standard and described in more detail the Synthetic/Natural Hybrid Coding (SNHC) subgroup that works on the coding of synthetic audiovisual object. We have covered in particular detail the part of SNHC that deals with the representation of human bodies and faces. We have tried to cover the objectives of particular groups and subgroups in MPEG4-SNHC rather then very low level technical detail.
[1] "MPEG-4: Context and Objectives", Rob Koenen, Fernando Pereira, Leonardo Chiariglione, Image Communication Journal, Special Issue on MPEG-4, Vol. 9, No. 4, May 1997. (to appear)
[2] "MPEG-4: Audio/Video & Synthetic Graphics/Audio for Mixed Media", Peter Doenges, Tolga Capin, Fabio Lavagetto, Joern Ostermann, Igor Pandzic, Eric Petajan, Image Communication Journal, Special Issue on MPEG-4, Vol. 9, No. 4, May 1997. (to appear)
[3] "SNHC Application Objectives and Requirements", Peter Doenges, Frederic Jordan, Igor Pandzic, ISO/IEC JTC1/SC29/WG11 N1316, MPEG96/July 1996.
[4] "Motor Functions in VLNET Body-Centered Networked Virtual Environment", I. S. Pandzic, T. Capin, N. Magnenat Thalmann, Daniel Thalamann, Virtual Environments and Scientific Visualization '96, Proc. of the Eurographics Workshops in Monte Carlo, Monaco and in Prague, Czech Republic (Springer), 1996.
[5] "Virtual Human Representation and Communication in VLNET Networked Virtual Environments", Tolga K. Capin, Igor S. Pandzic, Hansrudi Noser, Nadia Magnenat Thalmann, Daniel Thalmann, IEEE Computer Graphics and Applications, Special Issue on Multimedia Highways, 1997 (to appear)
[6] "Face and body definition and animation parameters", Eric Petajan, Igor Pandzic, Tolga Capin, Pei-Hwa Ho, Roberto Pockaj, Hai Tao, Homer Chen, Janice Shen, Pierre-Emmanuel Chaut, Joern Osterman, ISO/IEC JTC1/SC29/WG11 N1365, MPEG96/October 1996.
[7] "SNHC Verification Model Version 3.0", SNHC, ISO/IEC JTC1/SC29/WG11 N1545, MPEG97/February 1997.